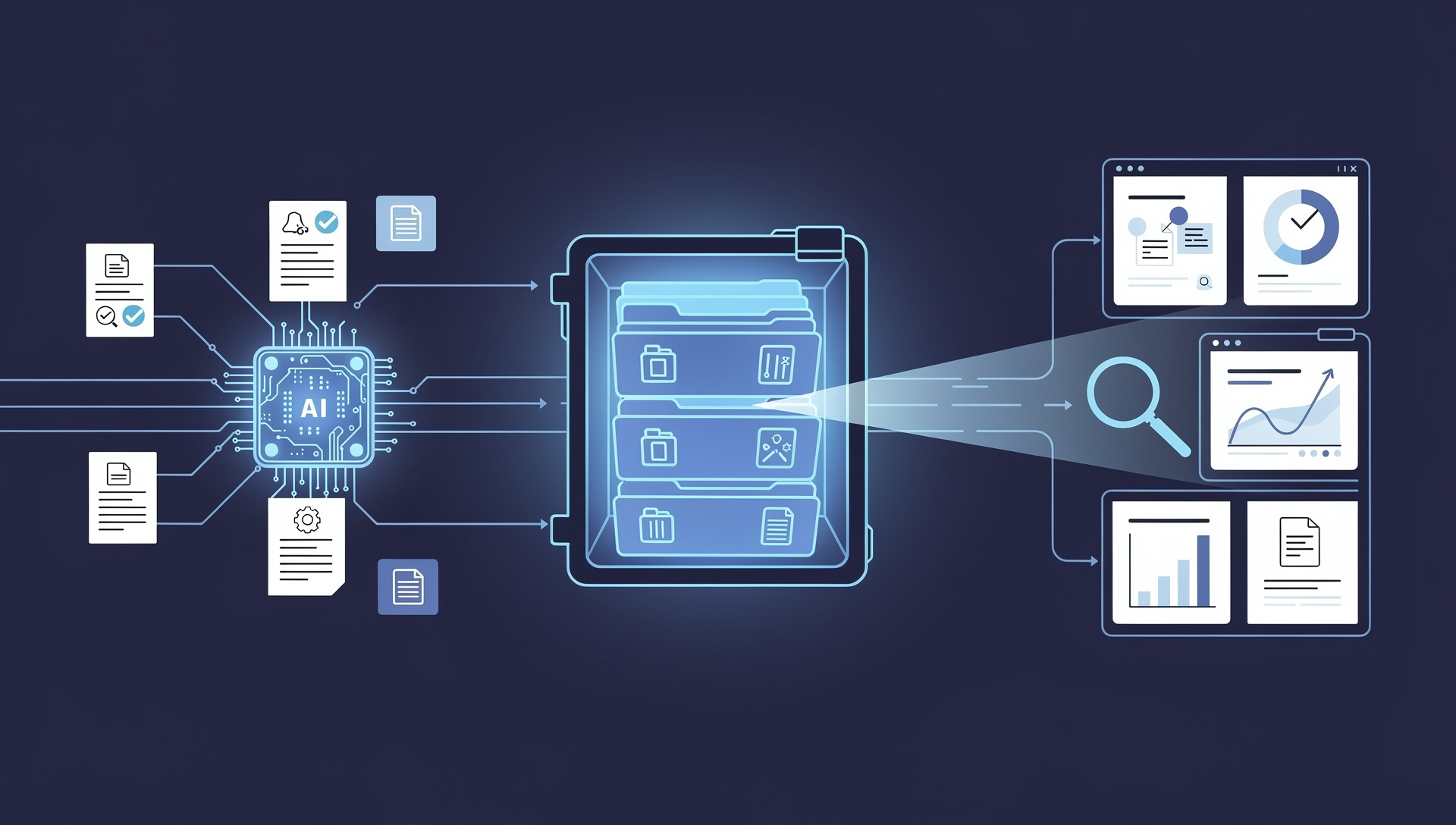
ระบบจัดการเอกสารองค์กร (Enterprise Content Management หรือ ECM) มีประโยชน์ได้เท่าที่ข้อมูลภายในมันมีคุณค่าเท่านั้น แพลตฟอร์มอย่าง Microsoft SharePoint, OpenText, M-Files, Alfresco และ Laserfiche เก่งในการจัดเก็บ จัดเวอร์ชัน รักษาความปลอดภัย และกำกับดูแลเอกสาร — แต่มันมองเอกสารส่วนใหญ่เป็นไฟล์ทึบ ใบแจ้งหนี้ที่สแกน สัญญาที่เซ็นแล้ว หรือแบบฟอร์ม KYC ที่อยู่ใน ECM ของคุณก็เป็นเพียง PDF ที่ไม่มีใครค้นหาตามเนื้อหา ส่งต่อตามข้อมูล หรือทำรายงานได้ OCR (Optical Character Recognition) และที่มากขึ้นเรื่อยๆ คือ AI ประมวลผลเอกสาร คือชั้นที่ปลดล็อกเนื้อหานั้น — เปลี่ยนเอกสารที่จัดเก็บทุกฉบับให้เป็นข้อมูลที่ค้นหาได้ จัดหมวดได้ และมีโครงสร้าง คำถามสำหรับองค์กรส่วนใหญ่ไม่ใช่ว่าจะเพิ่ม OCR ให้ ECM หรือไม่ แต่คือจะเลือกโซลูชันใด บทความนี้อธิบายว่าอะไรแยกโซลูชัน OCR ที่ดีสำหรับ ECM ออกจากตัวพื้นฐาน และจะประเมินตัวเลือกอย่างไรสำหรับองค์กรไทย
ตลาดมีตั้งแต่ OCR พื้นฐานที่ติดมากับแพลตฟอร์ม ECM เอง ไปจนถึง cloud OCR API แบบสแตนด์อโลน และแพลตฟอร์ม AI ประมวลผลเอกสารแบบครบวงจร ทั้งหมดไม่ใช่ของที่ใช้แทนกันได้ การเลือกผิดตัวหมายถึงการจ่ายเงินซื้อความสามารถที่คุณใช้ไม่ได้ หรือที่พบบ่อยกว่าคือ มารู้ทีหลังหลายเดือนว่า 'OCR' ที่คุณซื้อมารับมือเอกสารจริงของคุณไม่ได้ — ใบแจ้งหนี้ไทย-อังกฤษ สัญญาหลายเลย์เอาต์ แบบฟอร์มที่ประทับตราและสแกน นี่คือวิธีคิดเรื่องนี้
หมวดของโซลูชัน OCR สำหรับ ECM
- OCR ที่ติดมากับ ECM: แพลตฟอร์ม ECM ส่วนใหญ่มี OCR พื้นฐานเพื่อทำให้เอกสารที่สแกนค้นหาได้ SharePoint, Laserfiche และอื่นๆ จัดทำดัชนีข้อความจาก PDF และรูปภาพได้ ซึ่งดีพอสำหรับการค้นหาข้อความเต็ม แต่มันไม่ดึงฟิลด์เฉพาะ ไม่จัดหมวดประเภทเอกสารอย่างชาญฉลาด และรับมือเลย์เอาต์ไทยที่ซับซ้อนได้ไม่ดี
- Cloud OCR API แบบสแตนด์อโลน: บริการอย่าง Google Cloud Vision, Azure AI Document Intelligence และ AWS Textract ให้ OCR อเนกประสงค์ที่ทรงพลังซึ่งคุณเชื่อมต่อกับ ECM ผ่าน API มันแม่นยำกับเอกสารสะอาดและขยายได้ง่าย แต่เป็นแบบทั่วไป — การรองรับภาษาไทยและการดึงข้อมูลระดับฟิลด์แตกต่างกันไป และคุณต้องรับผิดชอบเรื่องการเชื่อมต่อและการเก็บข้อมูลในประเทศเอง
- แพลตฟอร์ม IDP / AI ประมวลผลเอกสารโดยเฉพาะ: โซลูชันที่สร้างมาเพื่อการประมวลผลเอกสารอัจฉริยะ — รวมถึง ABBYY, Hyperscience และ LuminexDoc — ผสาน OCR เข้ากับ AI เพื่อจัดหมวดเอกสาร ดึงฟิลด์ที่มีโครงสร้างโดยไม่ต้องใช้เทมเพลต ตรวจสอบข้อมูล และส่งเข้า ECM และระบบปลายทาง หมวดนี้ให้คุณค่ามากที่สุดสำหรับงานเอกสารปริมาณมาก หลากหลาย และสำคัญต่อธุรกิจ
- แนวทางผสม (Hybrid): องค์กรจำนวนมากใช้ OCR ในตัวของ ECM สำหรับการค้นหาทั่วไป และใช้แพลตฟอร์ม AI โดยเฉพาะกับประเภทเอกสารที่ขับเคลื่อนกระบวนการจริง — ใบแจ้งหนี้ สัญญา การเคลม ใบสมัคร ได้สิ่งที่ดีที่สุดจากทั้งสองโดยไม่ลงทุนเกินจำเป็นทุกจุด
'ดีที่สุด' หมายความว่าอย่างไรสำหรับ ECM
โซลูชัน OCR ที่ดีที่สุดไม่ใช่ตัวที่ได้คะแนน benchmark สูงสุดกับข้อความภาษาอังกฤษที่สะอาด — แต่คือตัวที่ทำงานได้กับเอกสารของคุณ และเข้ากับ ECM และกฎการกำกับดูแลของคุณ สำหรับการใช้งานในระบบจัดการเอกสารองค์กร ให้ประเมินโซลูชันด้วยเกณฑ์เหล่านี้:
- ความลึกในการเชื่อมต่อกับ ECM ของคุณ: มองหาคอนเนกเตอร์สำเร็จรูปสำหรับแพลตฟอร์มของคุณ — SharePoint, OpenText, M-Files, Alfresco, Laserfiche — พร้อม API แบบเปิด โซลูชันควรเขียน metadata และข้อมูลที่มีโครงสร้างกลับเข้า ECM เพื่อให้เอกสารค้นหาและส่งต่อได้ตามเนื้อหา ไม่ใช่แค่จัดเก็บ
- การดึงข้อมูลระดับฟิลด์ ไม่ใช่แค่ข้อความเต็ม: ข้อความที่ค้นหาได้คือขั้นต่ำ โซลูชันที่ดีที่สุดจัดหมวดเอกสารแต่ละฉบับและดึงฟิลด์เฉพาะที่กระบวนการของคุณต้องการ — ผู้ขาย ยอดเงิน วันที่ คู่สัญญา เลขประจำตัว — และเติมฟิลด์ metadata ของ ECM อัตโนมัติ
- การปรับตัวแบบไม่ต้องใช้เทมเพลต: รูปแบบเอกสารของคุณเปลี่ยนตลอด โซลูชันที่ต้องสร้างเทมเพลตใหม่ทุกเลย์เอาต์จะตามไม่ทัน การดึงข้อมูลด้วย AI ที่รู้จำฟิลด์ตามบริบทรับมือรูปแบบใหม่ได้ตั้งแต่วันแรก
- การรองรับภาษาไทยอย่างแท้จริง: สำหรับองค์กรไทยข้อนี้ชี้ขาด ทดสอบว่าโซลูชันเข้าใจภาษาไทยจริงหรือไม่ — แยกที่อยู่ไทย อ่านวันที่แบบ พ.ศ. และรับมือเอกสารปนไทย-อังกฤษ — ไม่ใช่แค่รู้จำตัวอักษรไทย
- ความแม่นยำและการตรวจสอบบนเอกสารจริง: เรียกร้องให้มี proof-of-concept บนไฟล์จริงของคุณ แพลตฟอร์มที่ดีที่สุดเพิ่มการให้คะแนนความมั่นใจและการตรวจสอบแบบ multi-model consensus เพื่อให้ผลลัพธ์ที่ความมั่นใจต่ำถูกคัดออกมา แทนที่จะถูกเขียนเข้า ECM อย่างเงียบๆ ราวกับเป็นข้อเท็จจริง
- การกำกับดูแล ความปลอดภัย และการติดตั้ง: ECM ของคุณมีอยู่ส่วนหนึ่งเพื่อการปฏิบัติตามกฎ ชั้น OCR ต้องเคารพสิ่งนั้น — ร่องรอยการตรวจสอบทุกการดึงข้อมูล การเข้าถึงตามบทบาท การจัดการข้อมูลที่สอดคล้อง PDPA และตัวเลือกการติดตั้งรวมถึงแบบ on-premises หรือคลาวด์ที่โฮสต์ในไทยสำหรับเนื้อหาที่ละเอียดอ่อน
- ต้นทุนรวมการเป็นเจ้าของ (TCO): คำนวณค่าลิขสิทธิ์ การเชื่อมต่อ ค่าเสริมสำหรับภาษาไทยและเอกสารเฉพาะ และต้นทุนต่อเนื่องของการตรวจสอบโดยคน ตัวเลือกที่ถูกที่สุดต่อหน้ามักไม่ใช่ต้นทุนรวมต่ำสุดเมื่อรวมการแก้ข้อผิดพลาดและการบำรุงรักษา
OCR ทำให้ ECM มีชีวิตขึ้นมาอย่างไร
ลองพิจารณาสถานการณ์ทั่วไป ใบแจ้งหนี้ผู้ขายและสัญญาหลายพันฉบับถูกสแกนเข้า SharePoint หรือ M-Files ทุกเดือน ถ้าไม่มี OCR อัจฉริยะ มันก็อยู่ตรงนั้นในฐานะ PDF — พนักงานยังต้องเปิดทีละฉบับเพื่อหาวันต่ออายุสัญญาหรือยอดเงินในใบแจ้งหนี้ และไม่มีอะไรทำรายงานอัตโนมัติได้ พอเพิ่มชั้น AI ประมวลผลเอกสาร เอกสารแต่ละฉบับจะถูกจัดหมวดตั้งแต่เข้ามา ฟิลด์สำคัญถูกดึงและเขียนเข้า metadata ของ ECM และเนื้อหาก็ค้นหาและทำรายงานได้เต็มที่ วันต่ออายุสัญญาตอนนี้กระตุ้นการแจ้งเตือนอัตโนมัติ ข้อมูลใบแจ้งหนี้ไหลเข้าระบบบัญชีและรายการที่จับคู่แล้วลิงก์กลับไปยัง PDF ที่จัดเก็บ ECM เดียวกันที่เคยเป็นตู้เก็บเอกสารแบบนิ่งๆ กลายเป็นระบบบันทึกที่ใช้งานได้ ค้นหาได้ และเป็นอัตโนมัติ — และสิ่งเดียวที่เปลี่ยนคือความฉลาดที่ใส่เข้าไปกับเอกสารขาเข้า
ECM ของคุณจัดเก็บเอกสาร OCR และ AI ทำให้มันใช้งานได้ โซลูชันที่ดีที่สุดคือตัวที่เปลี่ยนทุกไฟล์ในคลังของคุณให้เป็นข้อมูลที่ค้นหาได้ มีโครงสร้าง และนำไปทำงานต่อได้ — บนเอกสารของคุณ ในภาษาของคุณ ภายใต้กฎการกำกับดูแลของคุณ
LuminexDoc เข้ากับองค์กรไทยตรงไหน
LuminexDoc โดย WinnerSoft เป็นแพลตฟอร์ม AI ประมวลผลเอกสารที่ออกแบบมาเป็นชั้นความฉลาดให้กับระบบจัดการเอกสารองค์กรของคุณ มันไปไกลกว่า OCR พื้นฐานมาก: จัดหมวดเอกสาร ดึงฟิลด์ที่มีโครงสร้างโดยไม่ต้องใช้เทมเพลตต่อผู้ขาย ตรวจสอบผ่านการยืนยันแบบ 3-way AI consensus และเขียน metadata และข้อมูลที่สะอาดเข้าแพลตฟอร์ม ECM และระบบบัญชี ERP และ compliance ปลายทางผ่านคอนเนกเตอร์และ API เพราะมันถูกสร้างมาเพื่อองค์กรไทยโดยเฉพาะ — ด้วยความเข้าใจภาษาไทยแบบเนทีฟ รองรับวันที่แบบ พ.ศ. รองรับเอกสารสองภาษา ร่องรอยการตรวจสอบครบถ้วนสำหรับ PDPA และตัวเลือกการติดตั้งรวมถึงแบบ on-premises — มันจึงเข้ากับความเป็นจริงด้านการกำกับดูแลและภาษาที่เครื่องมือ OCR ระดับโลกแบบทั่วไปมองข้าม หากคุณกำลังประเมินโซลูชัน OCR เพื่อปลดล็อกเอกสารที่อยู่ใน ECM ของคุณอยู่แล้ว เชิญเยี่ยมชมหน้า LuminexDoc ที่ /luminexdoc หรือติดต่อทีมงานของเราที่ /contact เพื่อรับ proof-of-concept ฟรีด้วยเอกสารจริงของคุณ — เราจะแสดงความแม่นยำในการจัดหมวดและดึงข้อมูลบนเนื้อหาของคุณเอง เชื่อมต่อในแบบที่ระบบของคุณต้องการ


