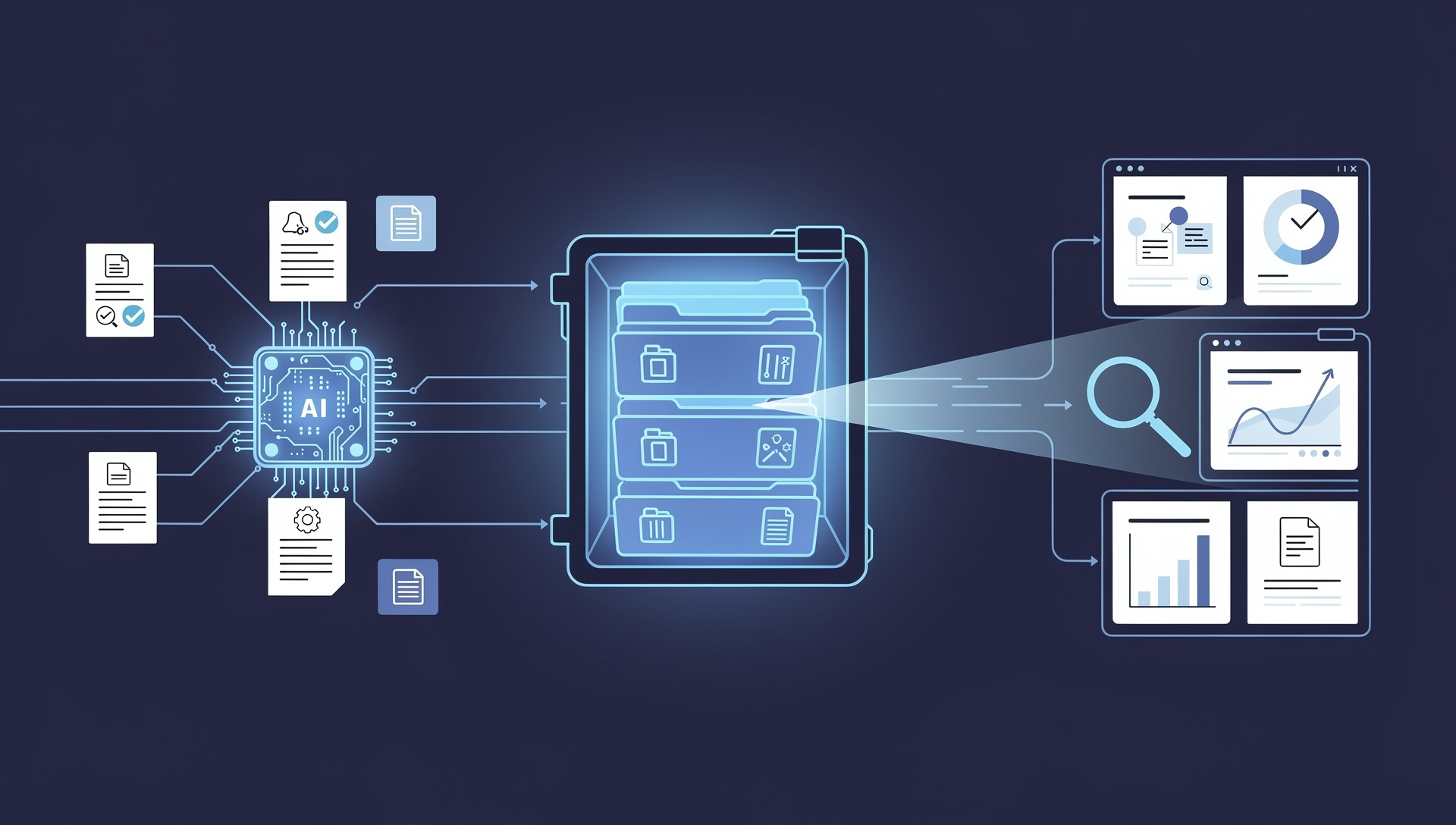
An Enterprise Content Management (ECM) system is only as useful as the data inside it. Platforms like Microsoft SharePoint, OpenText, M-Files, Alfresco, and Laserfiche are excellent at storing, versioning, securing, and governing documents — but they treat most documents as opaque files. A scanned invoice, a signed contract, or a KYC form sitting in your ECM is just a PDF that nobody can search by its contents, route by its data, or report on. OCR (Optical Character Recognition), and increasingly AI-powered document processing, is the layer that unlocks that content — turning every stored document into searchable, classified, structured data. The question for most organizations is not whether to add OCR to their ECM, but which solution to choose. This guide explains what separates a good OCR solution for ECM from a basic one, and how to evaluate the options for a Thai enterprise.
The market spans everything from the basic OCR built into ECM platforms themselves, to standalone cloud OCR APIs, to full AI document processing platforms. They are not interchangeable. Choosing the wrong one means either paying for capability you cannot use or, more commonly, discovering months later that the 'OCR' you bought cannot handle your real documents — your Thai-English invoices, your varied contract layouts, your stamped and scanned forms. Here is how to think about it.
The Categories of OCR Solutions for ECM
- Built-in ECM OCR: Most ECM platforms include basic OCR to make scanned documents searchable. SharePoint, Laserfiche, and others can index text from PDFs and images. This is fine for full-text search, but it does not extract specific fields, classify document types intelligently, or handle complex Thai layouts well.
- Standalone cloud OCR APIs: Services like Google Cloud Vision, Azure AI Document Intelligence, and AWS Textract offer powerful, general-purpose OCR you connect to your ECM via API. They are accurate on clean documents and scale easily, but they are generic — Thai language support and field-level extraction vary, and you carry the integration and data-residency responsibility.
- Dedicated IDP / AI document processing platforms: Solutions purpose-built for intelligent document processing — including ABBYY, Hyperscience, and LuminexDoc — combine OCR with AI to classify documents, extract structured fields without templates, validate the data, and push it into your ECM and downstream systems. This category delivers the most value for high-volume, high-variety, business-critical document workflows.
- Hybrid approaches: Many enterprises use their ECM's native OCR for general search and a dedicated AI platform for the document types that drive real processes — invoices, contracts, claims, applications. This gets the best of both without over-investing everywhere.
What 'Best' Actually Means for ECM
The best OCR solution is not the one with the highest benchmark score on clean English text — it is the one that performs on your documents and fits your ECM and your governance rules. For an enterprise content management deployment, evaluate solutions against these criteria:
- Integration depth with your ECM: Look for pre-built connectors for your platform — SharePoint, OpenText, M-Files, Alfresco, Laserfiche — plus an open API. The solution should write extracted metadata and structured data back into the ECM so documents become findable and routable by their content, not just stored.
- Field-level extraction, not just full-text: Searchable text is the minimum. The best solutions classify each document and extract the specific fields your processes need — vendor, amount, dates, parties, ID numbers — and populate ECM metadata fields automatically.
- Template-free adaptability: Your document formats change constantly. A solution that needs a new template for every layout will fall behind. AI-based extraction that recognizes fields by context handles new formats on day one.
- Genuine Thai language support: For Thai enterprises this is decisive. Test whether the solution truly understands Thai — parsing Thai addresses, reading Buddhist-era dates, and handling mixed Thai-English documents — rather than just recognizing Thai characters.
- Accuracy and validation on real documents: Demand a proof-of-concept on your actual files. The best platforms add confidence scoring and multi-model consensus validation so low-confidence results are flagged rather than silently written into your ECM as fact.
- Governance, security, and deployment: Your ECM exists partly for compliance. The OCR layer must respect that — audit trails for every extraction, role-based access, PDPA-aligned data handling, and deployment options including on-premises or Thai-hosted cloud for sensitive content.
- Total cost of ownership: Account for licensing, integration, Thai-language and custom-document surcharges, and the ongoing cost of human review. The cheapest per-page option is rarely the lowest total cost once error correction and maintenance are included.
How OCR Brings an ECM to Life
Consider a typical scenario. Thousands of supplier invoices and contracts are scanned into SharePoint or M-Files every month. Without intelligent OCR, they sit there as PDFs — staff still open each one to find a contract's renewal date or an invoice's amount, and nothing can be reported on automatically. Add an AI document processing layer, and each document is classified on arrival, its key fields are extracted and written into ECM metadata, and the content becomes fully searchable and reportable. A contract's renewal date now triggers an automatic reminder. An invoice's data flows into the accounting system and the matched record links back to the stored PDF. The same ECM that was a passive filing cabinet becomes an active, queryable, automated system of record — and the only thing that changed was the intelligence applied to the documents going in.
Your ECM stores documents. OCR and AI make them usable. The best solution is the one that turns every file in your repository into searchable, structured, actionable data — on your documents, in your language, under your governance rules.
Where LuminexDoc Fits for Thai Enterprises
LuminexDoc by WinnerSoft is an AI document processing platform designed to be the intelligence layer for your enterprise content management system. It goes well beyond basic OCR: it classifies documents, extracts structured fields without per-vendor templates, validates them through a 3-way AI consensus check, and writes clean metadata and data into ECM platforms and downstream accounting, ERP, and compliance systems via connectors and API. Because it is purpose-built for Thai enterprises — with native Thai language understanding, Buddhist-era date handling, bilingual document support, full audit trails for PDPA, and flexible deployment including on-premises — it fits the governance and language realities that generic global OCR tools miss. If you are evaluating OCR solutions to unlock the documents already sitting in your ECM, visit our LuminexDoc page at /luminexdoc or contact our team at /contact for a free proof-of-concept using your real documents — we will show you the classification and extraction accuracy on your own content, integrated the way your systems require.


