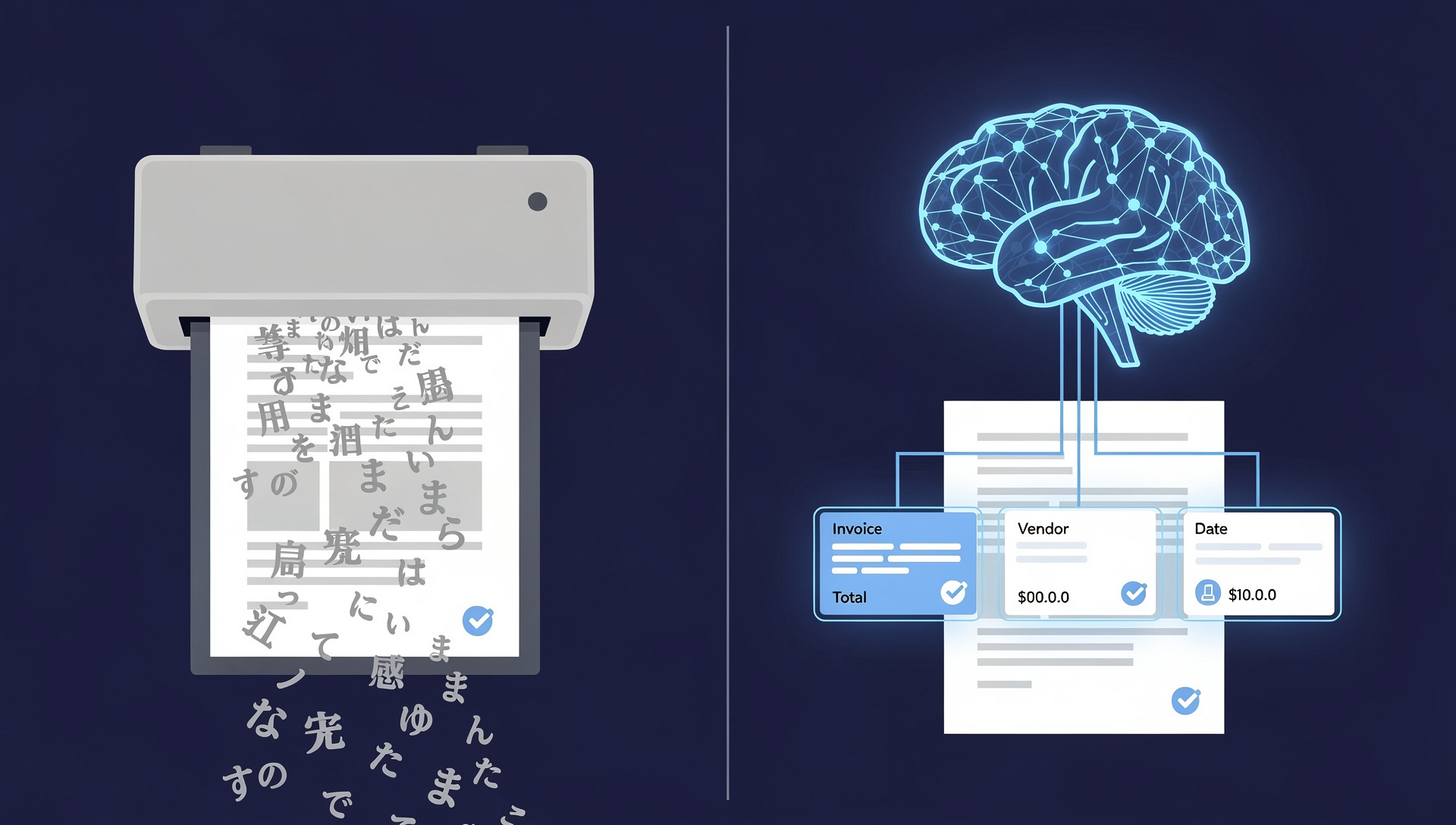
หลายคนใช้คำว่า "AI" และ "OCR" ราวกับเป็นสิ่งเดียวกัน แต่ความจริงไม่ใช่ OCR (Optical Character Recognition) คือเทคโนโลยีที่มีมานานหลายสิบปี ทำหน้าที่แปลงภาพของตัวอักษร — เช่นหน้าเอกสารที่สแกนหรือรูปถ่าย — ให้กลายเป็นข้อความที่คอมพิวเตอร์อ่านได้ ส่วน AI ประมวลผลเอกสาร เป็นหมวดเทคโนโลยีสมัยใหม่ที่กว้างกว่า ใช้ทั้ง computer vision, natural language processing และ machine learning ไม่ใช่แค่ "อ่านตัวอักษร" แต่ "เข้าใจ" ว่าเอกสารหมายถึงอะไรและดึงข้อมูลที่คุณต้องการออกมาให้ พูดง่ายๆ คือ OCR บอกคุณว่าบนหน้ากระดาษมีตัวอักษรอะไรบ้าง แต่ AI บอกได้ว่า '฿1,284,500' คือยอดรวมทั้งสิ้น ผู้ขายจดทะเบียนเลขผู้เสียภาษี 0105551xxxxxx และใบแจ้งหนี้นี้ครบกำหนดชำระใน 30 วัน สำหรับองค์กรที่ต้องการทำระบบอัตโนมัติให้กับใบแจ้งหนี้ สัญญา หรือแบบฟอร์ม การเข้าใจความแตกต่างนี้คือเส้นแบ่งระหว่างโครงการที่สำเร็จกับโครงการที่ล้มเหลวอย่างเงียบๆ
ความสับสนนี้มีผลกระทบจริง หลายบริษัทในไทยซื้อเครื่องมือที่โฆษณาว่าเป็น "AI ประมวลผลเอกสาร" แล้วพบภายหลังว่าจริงๆ เป็นเพียง OCR ที่มีตัวแก้ไขเทมเพลต และล้มเลิกโครงการไปหลังจากความแม่นยำไม่เป็นไปตามคาดอยู่หลายเดือน ขณะที่บางองค์กรกลับลงทุนเกินจำเป็นกับปัญหาที่ OCR ธรรมดาก็แก้ได้ บทความนี้จะอธิบายให้ชัดว่า OCR สิ้นสุดตรงไหนและ AI เริ่มต้นตรงไหน เพื่อให้คุณเลือกแนวทางที่เหมาะกับเอกสารของคุณ — และเข้าใจว่าทำไม LuminexDoc จึงถูกสร้างขึ้นเป็นแพลตฟอร์ม AI ไม่ใช่เครื่องมือ OCR อีกตัวหนึ่ง
OCR ทำอะไรได้จริงบ้าง
OCR เป็นเทคโนโลยีการจับคู่รูปแบบ (pattern-matching) มันสแกนภาพ ระบุรูปทรงที่ดูเหมือนตัวอักษรและตัวเลข แล้วแสดงผลออกมาเป็นข้อความที่แก้ไขได้ ซึ่งมีประโยชน์จริง — OCR คือสิ่งที่ทำให้คุณเปลี่ยน PDF ที่สแกนมาให้ค้นหาได้ หรือคัดลอกข้อความจากรูปภาพ OCR สมัยใหม่ทำงานเร็ว ราคาถูก และแม่นยำพอใช้กับข้อความพิมพ์ที่สะอาดและจัดเรียงตรง แต่ OCR ไม่เข้าใจ "ความหมาย" มันไม่รู้ว่า '12/06/2569' เป็นวันที่ในใบแจ้งหนี้หรือวันที่ส่งของ มันบอกไม่ได้ว่าชื่อผู้ขายสองชื่อหมายถึงบริษัทเดียวกัน มันแสดงผลเป็นข้อความเรียงต่อกันแล้วปล่อยให้การตีความทั้งหมดเป็นหน้าที่ของคุณ — ซึ่งมักเป็นคน หรือชุดกฎและเทมเพลตที่เปราะบาง
- OCR แปลงภาพเป็นข้อความ — นั่นคืองานทั้งหมดของมัน คือการรู้จำตัวอักษร ไม่ใช่การเข้าใจมัน
- OCR ต้องการโครงสร้าง — เพื่อดึงข้อมูลเฉพาะฟิลด์ OCR แบบดั้งเดิมต้องอาศัยเทมเพลตตายตัวที่กำหนดว่า 'ข้อความในกรอบนี้คือเลขที่ใบแจ้งหนี้' พอเลย์เอาต์เปลี่ยน เทมเพลตก็พัง
- OCR ไม่ตรวจสอบความถูกต้อง — มันจะแสดงเลข '8' แทนเลขจริงที่เป็น '6' โดยไม่รู้เลยว่าค่านั้นผิด
- OCR รับมือกับโลกความจริงที่ยุ่งเหยิงได้ยาก — เอกสารสแกนเอียง ตราประทับทับข้อความ ลายมือ บรรทัดที่ปนไทย-อังกฤษ และรูปถ่ายจากมือถือความละเอียดต่ำ ล้วนทำให้ความแม่นยำของ OCR ลดลงอย่างรวดเร็ว
AI เพิ่มอะไรเข้าไปบ้าง
ระบบประมวลผลเอกสารด้วย AI ใช้ OCR เป็นองค์ประกอบหนึ่ง — คือขั้นตอนการอ่านตัวอักษร — แล้วเสริมความฉลาดเข้าไปบนนั้น โมเดล computer vision ระบุตำแหน่งตาราง ลายเซ็น โลโก้ และตราประทับ ไม่ว่ามันจะอยู่ตรงไหนของหน้า natural language processing เข้าใจบริบท: มันรู้ว่า 'ยอดรวมทั้งสิ้น', 'Grand Total' และ 'Total Amount Due' ล้วนชี้ไปที่แนวคิดเดียวกัน แม้คำและตำแหน่งจะต่างกันในแต่ละผู้ขาย โมเดล machine learning ที่ฝึกจากเอกสารหลายพันฉบับจะคาดการณ์ค่าที่ถูกต้องที่สุดของแต่ละฟิลด์ — และเก่งขึ้นทุกครั้งที่มีคนแก้ไข ผลลัพธ์คือระบบที่ดึงข้อมูลที่คุณต้องการจริงๆ จากเอกสารที่ไม่เคยเห็นมาก่อน โดยไม่ต้องสร้างเทมเพลตให้ทุกเลย์เอาต์
- AI เข้าใจความหมาย ไม่ใช่แค่ตัวอักษร — มันจับคู่ถ้อยคำที่หลากหลายและยุ่งเหยิงเข้ากับฟิลด์ที่คุณต้องการ ทั้งผู้ขาย เลขผู้เสียภาษี รายการสินค้า วันครบกำหนด และ VAT ข้ามเลย์เอาต์นับพันแบบ
- AI ไม่ต้องใช้เทมเพลต — เพราะมันรู้จำรูปแบบเชิงบริบท จึงประมวลผลใบแจ้งหนี้รูปแบบใหม่ได้ตั้งแต่วันแรกโดยไม่ต้องให้ใครสร้างเทมเพลตก่อน
- AI รับมือเนื้อหาที่ไม่มีโครงสร้างได้ — สัญญา อีเมล ลายมือ และหมายเหตุข้อความอิสระ ซึ่งเป็นจุดที่ OCR เพียงอย่างเดียวให้ผลลัพธ์ที่ใช้งานไม่ได้ คือจุดที่ AI ดึงข้อมูลที่มีความหมายออกมาได้
- AI ตรวจสอบและให้คะแนนความมั่นใจ — แพลตฟอร์มสมัยใหม่รันหลายโมเดลแล้วเปรียบเทียบผลลัพธ์ คัดเฉพาะค่าที่ไม่แน่ใจจริงๆ ให้คนตรวจ แทนที่จะส่งค่าผิดออกมาเงียบๆ
- AI เรียนรู้ตามเวลา — ทุกการแก้ไขทำให้โมเดลแม่นยำขึ้นกับเอกสารที่คล้ายกัน ความแม่นยำจึงไต่ขึ้นไปสู่ 99% ตลอดหลายเดือนของการใช้งาน — สิ่งที่ OCR แบบตายตัวทำไม่ได้เลย
AI กับ OCR: เทียบกันชัดๆ
- เป้าหมาย — OCR: เปลี่ยนภาพเป็นข้อความ / AI: เปลี่ยนเอกสารเป็นข้อมูลธุรกิจที่มีโครงสร้างและผ่านการตรวจสอบ
- เลย์เอาต์เปลี่ยน — OCR: ต้องสร้างเทมเพลตใหม่ทุกรูปแบบ / AI: ปรับตัวอัตโนมัติกับรูปแบบที่ไม่เคยเห็น
- ความแม่นยำกับเอกสารจริง — OCR: ราว 70-85% และลดลงอีกเมื่อสแกนไม่ดี / AI: 95-98% และดีขึ้นเมื่อใช้งาน
- ภาษาไทย — OCR: อ่านตัวอักษรไทยได้แต่สับสนกับวรรณยุกต์ การเว้นวรรค และข้อความปนไทย-อังกฤษ / AI: แยกที่อยู่ไทย วันที่ พ.ศ. และข้อความสองภาษาได้ด้วยความเข้าใจภาษาอย่างแท้จริง
- การจัดการข้อผิดพลาด — OCR: ส่งค่าผิดออกมาเงียบๆ / AI: คัดฟิลด์ที่ความมั่นใจต่ำให้ตรวจสอบผ่าน consensus validation
- เหมาะกับงานแบบใด — OCR: แปลงหน้าเอกสารพิมพ์ที่สะอาดเพื่อค้นหา/จัดเก็บ / AI: ทำระบบอัตโนมัติงานปริมาณมากและหลากหลาย เช่น เจ้าหนี้การค้า KYC และสัญญา
ตัวอย่างจริง: การอ่านใบแจ้งหนี้
ลองนึกภาพใบแจ้งหนี้ผู้ขาย 500 ฉบับเข้ามาทุกเดือนจากผู้ขาย 80 ราย ทั้งไทยและอังกฤษ บางฉบับสแกน บางฉบับส่งเป็น PDF ทางอีเมล บางฉบับถ่ายจากมือถือ ด้วย OCR เพียงอย่างเดียว คุณจะได้ข้อความ 500 ก้อน หากต้องการดึงผู้ขาย เลขผู้เสียภาษี รายการสินค้า และยอดรวม คุณต้องสร้างและดูแลเทมเพลตให้ครบทั้ง 80 เลย์เอาต์ — และทุกครั้งที่ผู้ขายเปลี่ยนรูปแบบ การประมวลผลก็พังจนกว่าจะมีคนมาแก้เทมเพลต แต่ด้วย AI ประมวลผลเอกสาร ระบบจะอ่านใบแจ้งหนี้แต่ละฉบับ รู้จำฟิลด์ที่เกี่ยวข้องจากบริบทไม่ว่ามันจะอยู่ตรงไหน ตรวจสอบตัวเลขข้ามหลายโมเดล แล้วส่งข้อมูลสะอาดเข้าระบบบัญชีของคุณโดยตรง รูปแบบผู้ขายใหม่ถูกจัดการอัตโนมัติ เวลาประมวลผลต่อฉบับลดจากราว 15 นาทีเหลือไม่ถึง 30 วินาที และค่าที่ต้องให้คนตรวจก็ถูกคัดแยกชัดเจน ไม่ใช่ฝังอยู่ในกองข้อมูล
เมื่อไหร่ OCR ก็พอ — และเมื่อไหร่ต้องใช้ AI
OCR เพียงอย่างเดียวเป็นทางเลือกที่ดีเมื่อเป้าหมายของคุณคือทำให้เอกสารค้นหาได้ หรือแปลงแบบฟอร์มที่สะอาด สม่ำเสมอ และมีเลย์เอาต์เดียวให้เป็นดิจิทัล หากคุณกำลังสแกนคลังรายงานที่พิมพ์ไว้เพื่อให้คนค้นหา OCR ทำงานได้ดีในต้นทุนต่ำ แต่เมื่อใดที่เป้าหมายเปลี่ยนจาก 'อ่านข้อความ' ไปเป็น 'ดึงข้อมูลเฉพาะที่เชื่อถือได้แล้วป้อนเข้ากระบวนการธุรกิจ' — โดยเฉพาะข้ามหลายรูปแบบ เป็นภาษาไทย และในปริมาณมาก — OCR เพียงอย่างเดียวจะพาคุณไปไม่ถึง นั่นคือจุดที่ AI ประมวลผลเอกสารกลายเป็นสิ่งจำเป็น ไม่ใช่ทางเลือก ทดสอบง่ายๆ คือ ถ้าตอนนี้ต้องมีคนอ่านเอกสารแต่ละฉบับแล้วตัดสินว่าข้อมูลหมายถึงอะไร แสดงว่าคุณต้องการ AI ไม่ใช่แค่ OCR
OCR อ่านตัวอักษร AI เข้าใจเอกสาร ระบบอัตโนมัติจะได้ผลก็ต่อเมื่อซอฟต์แวร์ของคุณทำส่วนที่สอง ไม่ใช่แค่ส่วนแรก
LuminexDoc เข้ามาตรงไหน
LuminexDoc โดย WinnerSoft เป็นแพลตฟอร์ม AI ประมวลผลเอกสาร ไม่ใช่เครื่องมือ OCR มันใช้ OCR ภายในเป็นชั้นอ่านตัวอักษร แล้วใช้ AI เข้าใจเอกสารแต่ละฉบับ ดึงฟิลด์ที่คุณต้องการ และตรวจสอบความถูกต้องผ่านการยืนยันแบบ 3-way AI consensus ที่คัดเฉพาะค่าที่ไม่แน่ใจจริงๆ ให้ตรวจสอบ มันถูกสร้างมาเพื่อองค์กรไทยโดยเฉพาะ — ด้วยความเข้าใจภาษาไทยแบบเนทีฟ รองรับวันที่แบบ พ.ศ. รองรับเอกสารสองภาษา และตัวเลือกการติดตั้งที่ยืดหยุ่นรวมถึงแบบ on-premises สำหรับองค์กรที่มีข้อกำหนดด้านการเก็บข้อมูลในประเทศอย่างเข้มงวด ผลลัพธ์คือการดึงข้อมูลแบบไม่ต้องใช้เทมเพลตที่ยังแม่นยำแม้ผู้ขายและรูปแบบจะเปลี่ยน เชื่อมต่อโดยตรงกับระบบบัญชีและ ERP ของคุณ และฉลาดขึ้นยิ่งใช้ยิ่งดี หากคุณเคยผิดหวังกับเครื่องมือ 'AI' ที่กลายเป็น OCR แฝงตัว เชิญเยี่ยมชมหน้า LuminexDoc ที่ /luminexdoc หรือติดต่อเราที่ /contact เพื่อรับการประเมินฟรีด้วยเอกสารจริงของคุณเอง — เราจะแสดงความแม่นยำบนข้อมูลของคุณ ไม่ใช่ตัวเลขมาตรฐานทั่วไป


